ArrayList的特点是顺序存储,导致其移动和删除需要大量的复制开销。因此出现了另外一种,非连续存储的结构,链表。它拥有高效的插入和删除(这里有个前提,是一直节点的具体位置),但是失去了高效访问的优点。
它的一些特点:
- 动态扩容: 因为它是不连续存储的,它不需要预先分配好一定的长度作为容器。理论上,内存足够的话,它可以无限拓展。
- 非并发安全: 非线程安全的容器
由于链表的组织是靠节点之间的指向来关联的,因此,一般插入或者删除等操作,都首先获取对应节点或者对应节点的前置节点。
链表是一组节点构成的序列,节点之间通过指针相连。每一个节点,都包含: 数据(该节点要存储的数据) 和 指针(指向其它节点)。(即数据域与指针域)
它的基本结构如下:

它包含一个头指针,它是一个哑节点,作用是为了方便操作使用。
各个节点的位置可以是离散的,最后一个节点指向一个"空"(NULL)。
typedef struct linked_node
{
Element e; // the value
struct linked_node *next; // next node
} LinkedNode;不同于顺序表的线性连接,由于逻辑上线性关联(位置相对固定),因此存储位置可以根据起始位置和索引求的。在单链表中,任何两个节点的物理地址没有固定关系,只能通过遍历求得。因此,其时间复杂度为O(N)。
Element find(unsigned int index, LinkedList *list)
{
if (index < 0 || index >= list->length)
{
return NULL;
}
int i = 0;
LinkedNode *node = list->root->next;
while (i < index)
{
node = node->next;
i++;
}
return node->e;
}无论是通过索引访问还是通过值访问链表,都需要确定该值在链表中的具体节点,然后在进行一系列其它操作,如删除、插入等操作,因此对于删除和插入来说,其时间复杂度为O(N)。
链表拥有高效的插入机制。它的基本插入过程为:
- 将目的节点的前驱节点(
prev)指向目的节点 - 将目的节点的指针指向原前驱节点的指向节点(
next)
图表表示如下:
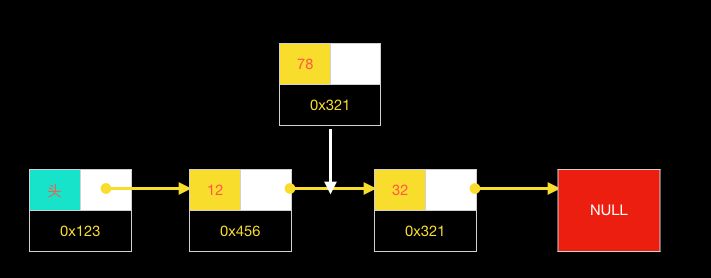
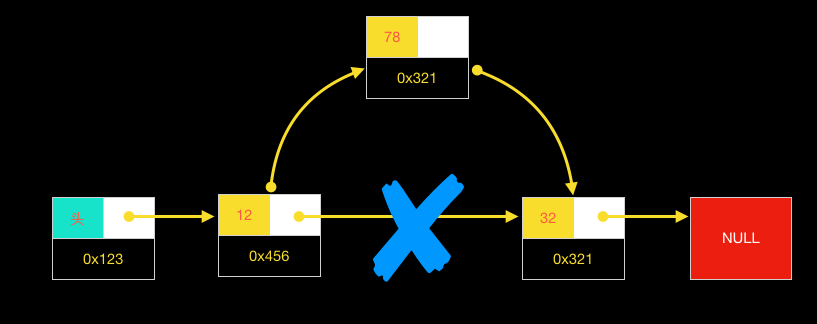
当插入位置是第一个位置时,这样就是用到了头节点(哑节点),此时就无需特别判断,即与其它插入过程一样。如果没有这个头节点,就必须单独判断是否插入到链表头,同事还要更新链表的根节点地址的指向。
链表的删除与插入类似,都是只需对目的地址的左右节点指向做修改。删除多了一步回收操作,即对删除的节点要手动内存回收,防止出现内存泄漏问题。
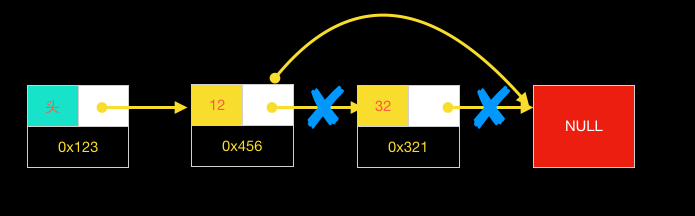
除了一些简单的单链表,还有一些变种线性结构,如:
由于它高效删除和插入的特点,且无需提前分配空间等优点,因此它是实现一些其它线性结构的基础。一些常见应用: